
本项目旨在利用先进的预训练语言模型技术,结合特定领域的专业知识,打造一个专注于无人机飞行安全规范的专家问答机器人。
项目以 DeepSeek-R1-Distill-Qwen-1.5B 作为基础模型,利用收集到的无人机安全飞行监控相关数据进行参数高效微调(PEFT)。最终目标是生成一个能够准确、结构化地回答无人机飞行安全和风险相关问题的专业问答模型,并能遵循特定的回答格式(包含思考过程)。
模型托管地址
微调后的模型已托管至 Hugging Face Hub,可通过以下地址访问(需科学上网):https://huggingface.co/GabrielCheng/Deepseek-r1-finetuned-drone-safty
国内可访问魔搭社区下载:https://www.modelscope.cn/models/gabrielai/Deepseek-r1-finetuned-drone-safty/
模型调用代码示意
可通过以下 Python 代码调用(Hugging Face Hub上托管)微调后的模型:
模型使用演示
这里展示了微调前后的效果对比:
技术实现
数据处理
- 数据来源:原始数据来源于 Hugging Face 平台的无人机云数据集 (pohsjxx/default-domain-cot-dataset)。
- 样本筛选与清洗:从中提取约 3500 个样本作为训练基础,并进行清洗。然后拆分为训练集(85%)和验证集(15%)。
- 关键处理 – 格式对齐:
- 调整了原数据集中 answer 字段的文字表述,使其更通用。
- 为了适配推理模型采用的“思考-回答”格式(Chain-of-Thought, CoT),我们将原数据集中的 reasoning(推理过程)字段和 answer(最终答案)字段进行了对调。即,将原始的 answer 内容作为模型的思考过程(放入 </think> 标签前),将原始的 reasoning 内容作为模型的最终正式回答。这一转换旨在使训练数据的格式更贴近 DeepSeek-R1 等模型常见的 CoT 数据模式。
微调训练
- 框架:采用 Hugging Face 的 transformers 和 peft 库,实现了 LoRA (Low-Rank Adaptation) 参数高效微调。
- 硬件平台:利用 Google Colab 提供的 T4 GPU (约 16GB 显存) 进行训练。
- 关键超参数设置与考量:
- 显存优化:针对 T4 显存限制,设置了较小的批次大小 (per_device_train_batch_size=2),并启用了梯度检查点 (gradient_checkpointing=True) 以节省显存(牺牲少量训练速度)。同时使用混合精度训练 (fp16=True)。
- 模拟大批次:通过梯度累积 (gradient_accumulation_steps=16),实现有效批次大小为 32 (2 * 16),有助于稳定训练。
- 防止过拟合:考虑到样本量(3500)相对较小,设置了 LoRA Dropout (lora_dropout=0.1) 和权重衰减 (weight_decay=0.01)。
- LoRA 配置:r=8, lora_alpha=32。
- 训练周期与学习率:num_train_epochs=5,learning_rate=1e-4,并使用 cosine 学习率调度器。
微调效果
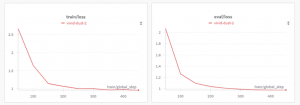
- 损失函数表现:训练集和验证集的损失均从初始的约 2.8 下降至 0.8 左右,且验证集损失未出现明显反弹,表明模型有效收敛且基本没有出现过拟合现象。
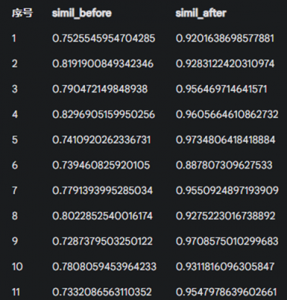
- 语义相似度提升:使用验证集数据,通过计算模型生成回答与标准答案之间的语义相似度(Sentence Transformers),发现微调后模型的平均相似度得分从 0.77 提升至 0.95 左右。这表明微调明显提高了模型回答内容与目标答案在语义层面上的一致性。
项目局限性
- 缺乏真实输入:当前的问答模式主要基于文本问题。真实的无人机安全监控场景往往需要结合飞行轨迹、环境感知等多模态数据作为输入。本模型未包含这部分数据和能力,主要目的是展示问答格式和领域知识上的一致性,实用性有限。
- 数据构造影响:训练数据中“思考”(<think>部分)和“回答”部分是通过对调原始数据集的 answer 和 reasoning 字段构造的。这两部分之间可能缺乏原生数据那样清晰、自然的逻辑关联,这可能对模型深度理解和生成真正连贯思考过程的能力造成一定阻碍。
- 基础模型的能力限制:考虑到 Google Colab T4 GPU 的算力与显存限制,本项目选取了 1.5B 参数量的 DeepSeek-R1-Qwen 蒸馏模型作为基础模型。虽然该规模的模型足以验证微调流程和概念,但在处理复杂或边缘问题时还是稳定性不足,时常出现回答格式混乱的情况。对于追求高稳定性和准确性的真实应用场景,建议选用参数量更大(如 7B 或以上)的基础模型进行微调。